Tworząc w IDE zapewne nieraz natknęliście się na kod źródłowy, który zawierał wulgaryzmy czy to w postaci komentarza, czy to w postaci nazw zmiennych. Również my sami lubimy wstawić gdzieś w kodzie "kupę" lub inny równie ciekawy zwrot.
Niestety czasem takie "kwiatki" wychodzą na produkcję i nie są może czymś karygodnym lub niebezpiecznym, ale wizerunkowo raczej nikt na tym nie zyskuje. Ostatnio pisał Niebezpiecznik chociażby o "fakach" na stronce OKE
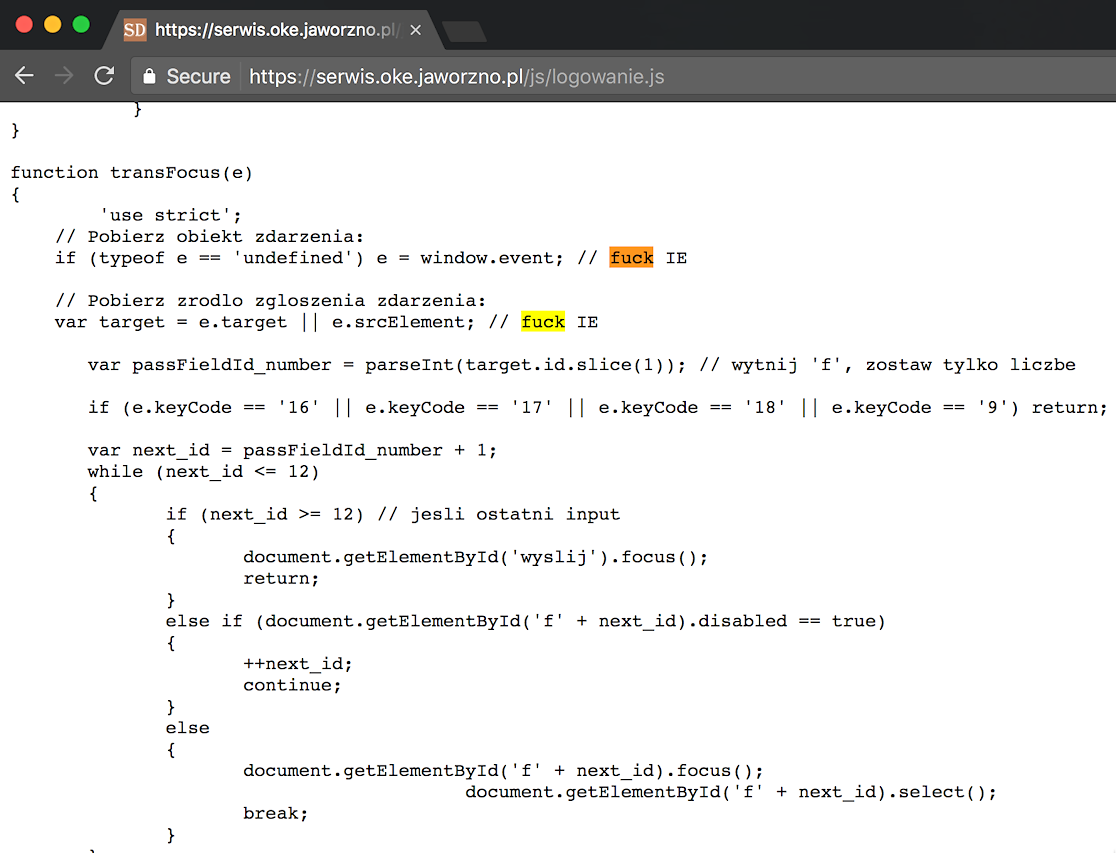
a kilka dni wcześniej podobnie "wpadł" Citibank.
Tworząc na konkurs wtyczkę Healthy With VS wpadłem na pomysł, aby stworzyć dodatek do Visual Studio, który mógłby zaradzić takim problemom. Bad Word Detector, bo tak nazwałem ten nano-projekt, wykrywa wulgaryzmy w kodzie źródłowym edytora i je zaznacza. Obecnie jest to dopiero pierwsza wersja, ale mimo to już może być przydatna.
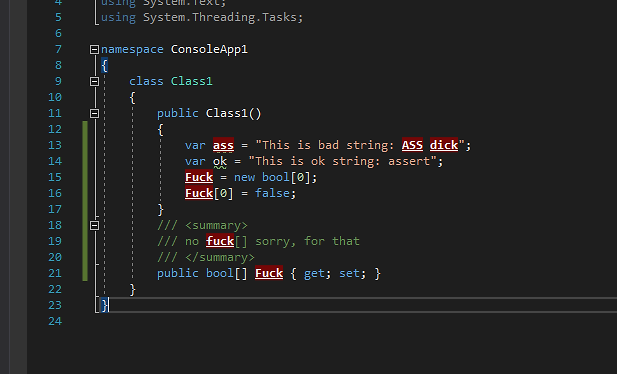
Lista wulgaryzmów obecnie ograniczona jest do języka angielskiego, ale w przyszłości będzie rozszerzona o inne języki, w tym polski. Baza słów została zaczerpnięta z projektu na GitHbie LDNOOBW, czyli List of Dirty, Naughty, Obscene, and Otherwise Bad Words . Tak, takie rzeczy też można znaleźć na GitHubie :)
Projekt jest już gotowy do przetestowania w Visual Studio. Można go pobrać z marketu: Bad Word Detector lub z poziomu IDE.
Źródła projektu dostępne są na GitHubie.
Teraz trochę o tym jak taka wtyczka została zrobiona.
Jak działa Bad Word Detector?
Tworzymy nowy projekt w VS typu VSIXProject (gałąź Extensibility). Następnie do pustego projektu dodajemy element Editor Classifier
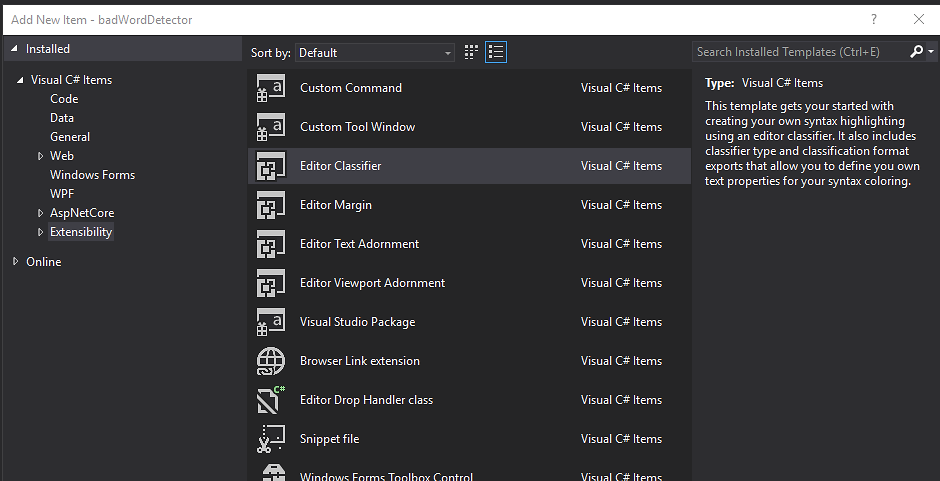
Ten szablon pozwoli na stworzenie wtyczki, która będzie kolorowała składnię w Visual Studio.
Dostaniemy tutaj m.in.
EditorClassifierFormat , który odpowiada za formatowanie kolorowania składni
EditorClassifier przesyłający kawałki edytora tekstu, które się zmieniły, w celu analizy czy należy zastosować formatowanie lub nie
W tym przypadku nasz plik BadWordEditorClassifierFormat posiada następujący opis formatowania
this.DisplayName = "BadWordEditorClassifier"; // Human readable version of the name
this.BackgroundColor = Colors.DarkRed;
this.ForegroundColor = Colors.WhiteSmoke;
this.TextDecorations = System.Windows.TextDecorations.Underline;
this.IsBold = true;
Jest tu informacja o kolorach zaznaczenia i pogrubieniu, a także nazwa.
W tym miejscu zaznaczamy także za pomocą atrybutów, aby nasz klasyfikator był odpalany na końcu poprzez ustawienie Order :
[Export(typeof(EditorFormatDefinition))]
[ClassificationType(ClassificationTypeNames = "BadWordEditorClassifier")]
[Name("BadWordEditorClassifier")]
[UserVisible(true)] // This should be visible to the end user
[Order(After = Priority.High)] // Set the priority
internal sealed class BadWordEditorClassifierFormat : ClassificationFormatDefinition
{
//...
}
Sprawdzenie czy wtyczka powinna zaznaczyć tekst odbywa się w klasie BadWordEditorClassifier w metodzie GetClassificationSpans . Wygląda ona następująco:
public IList<ClassificationSpan> GetClassificationSpans(SnapshotSpan span)
{
var result = new List<ClassificationSpan>();
var badDetails = BadService.Instance.BadWordsDetails(span.GetText());
if (badDetails != null)
{
badDetails.ForEach(x =>
{
result.Add(new ClassificationSpan(new SnapshotSpan(span.Snapshot,
(span.Span.Start + x.StartIndex), x.Length), this.classificationType));
});
}
return result;
}
GetClassificationSpans jako parametr ma analizowany tekst z edytora. Metoda sprawdza zewnętrznym serwisem BadService , czy w zaznaczonym tekście są wulgaryzmy. Jeśli tak, wówczas w pętli tworzy elementy z edytora jakie powinny zostać zaznaczone za pomocą naszego formatera. Metoda BadWordsDetails zwraca początkowy indeks z wulgaryzmem i jego długość. Pozwala to na dokładne określenie miejsca do podkreślenia.
Sam BadService jest Singletonem i przy pierwszym odwołaniu zaczytuje wulgaryzmy z pliku do pamięci. Detekcja sprowadza się do użycia Regexów:
public List<BadWordInfo> BadWordsDetails(string input)
{
if (input != null && OnlyAlphaRegex.IsMatch(input))
{
List<BadWordInfo> indexList = new List<BadWordInfo>();
BadList.ForEach(bad =>
{
var badMatch = Regex.Match(input, @"\b" + bad + @"\b", RegexOptions.IgnoreCase);
while (badMatch.Success)
{
indexList.Add(new BadWordInfo(badMatch.Index, bad.Length));
badMatch = badMatch.NextMatch();
}
});
return indexList.Any() ? indexList : null;
}
return null;
}
Na początku sprawdzamy czy tekst do analizy nie jest pusty i czy ma jakieś znaki z alfabetu. Te ostatnie jest robione przy pomocy skompilowanego Regexa:
private Regex OnlyAlphaRegex = new Regex(@"[a-zA-Z]", RegexOptions.Compiled);
Następnie iterujemy po kolejnych słowach i sprawdzamy czy całe przekleństwo (nie wyraz w środku ) występuje w tekście. Jeśli tak, to zapisujemy miejsce wystąpienia i długość wulgaryzmu. W jednym fragmencie może być kilka wystąpień , stąd też brane pod uwagę są wszystkie detekcje.
I oto główny core wtyczki Bad Word Detector. W przyszłości planuję dodanie innych języków z możliwością aktywacji ich w ustawieniach. Zapraszam do testów i zgłaszania uwag. Mam nadzieję, że wtyczka będzie przydatna :)
Pobierz: Bad Word Detector
Komentarze
Prześlij komentarz