Portalowa aplikacja DePesza jest już od jakiegoś czasu w Sklepie Windows. Prace nad doszlifowaniem programu i dodaniem nowych elementów trwają i jeszcze przed końcem maja pojawi się w markecie nowa wersja. Dziś jednak chciałbym przedstawić mały element, który zostanie dodany w kolejnym wydaniu DePeszy - statystyki blogowe.

Parsowanie HTML w C# - Html Agility Pack
Logowanie lub pobieranie z portalu powiadomień można było oprzeć na wymianie zapytań pomiędzy aplikacją DePesza, a serwerem dobrychprogramów (wystawiony serwis). Niestety, jeśli zechcemy uzyskać statystyki odnośnie wpisów blogowych zalogowanej osoby, musimy pokusić się o czyste parsowanie HTML.
Z tym problemem poradzimy sobie szybko przy pomocy Html Agility Pack. Jest to najlepsza biblioteka .NET do parsowania HTML. Możliwość ma ona ogromne i działa zarówno na desktopie, aplikacji mobilnej, jak i platformie Universal Windows Platform. Obsługa jej jest bardzo prosta i szybka (daaawno temu użyta przy zabawie z globalnymi statystykami portalu: dobreprogramy.pl w liczbach 2012 - 2013 ).
Licznik Blogowy - zapomniana wtyczka
Ponad wa lata temu stworzyłem wtyczkę do przeglądarek internetowych (Chrome/Firefox/Opera), która gromadziła statystyki blogowe dla zalogowanej osoby na portalu (linki: Licznik Blogowy, Licznik Blogowy - aktualizacja ). Zasada uzyskiwania danych była dość prosta, stworzona w JavaScripcie, ale bardzo skuteczna i szybka. Dzięki temu, iż blog przez ponad dwa lata nie zmienił się zupełnie, od strony zarządzania wpisami blogowymi, Licznik Blogowy działa nadal.
Pobieranie danych opiera się na poniższym pomyśle, którego podstawowe założenia zostaną użyte również przy uzyskiwaniu statystyk do DePeszy.
Pobieranie statystyk - opis
Punktem wyjściowym jest strona:
http://www.dobreprogramy.pl/MojBlog.html
do której dostęp mają osoby zalogowane. W tym miejscu znajdziemy listę ze wszystkimi wpisami danego uzytkownika portalu:
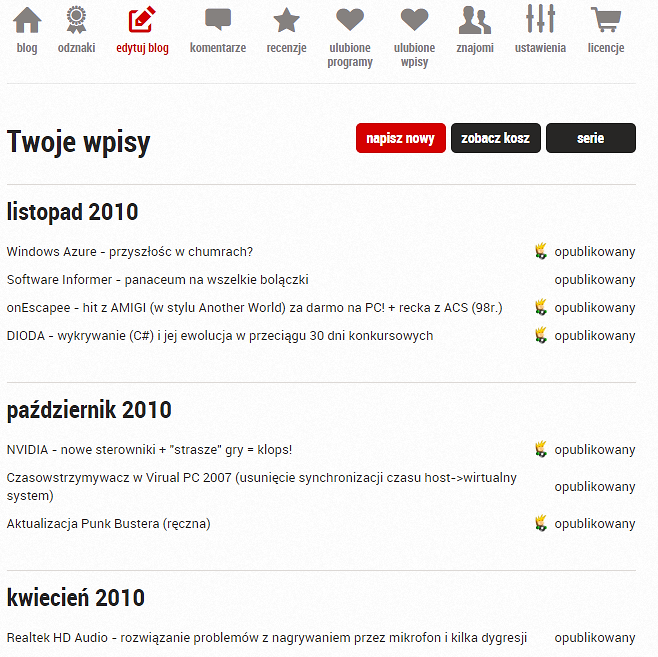
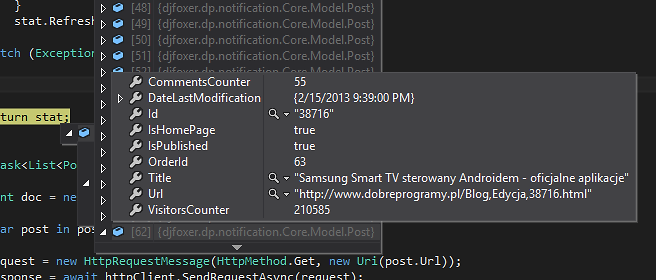
Każda pozycja na liście posiada tytuł, link do wpisu z edycją (tu także w url mamy ID wpisu) oraz status. Ten ostatni określa czy post wylądował na głównej stronie bloga, a także czy jest dopiero tworzony lub został już opublikowany. Te dane pozwolą na dostanie się do szczegółowych informacji o każdym z wpisów.
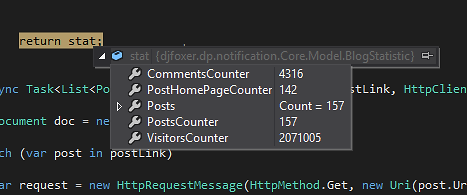
Posiadając listę z linkami do edycji, będziemy wchodzili do każdego wpisu (edycja) w celu pobrania: daty ostatniej zmiany, liczby wyświetleń i komentarzy:
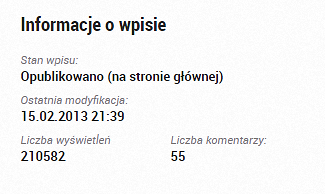
Oczywiście lista z blogami jest stronicowa, zatem całość będzie działać rekurencyjnie:

Pobieranie statystyk - parsowanie HTML za pomocą Html Agility Pack w C#
Przejdźmy zatem do samej implementacji. Wyłuskiwanie informacji z HTML poprzez Agility Pack można uzyskać dwojako: poprzez XPath (język służący do adresowania części dokumentu XML) lub za pomocą zapytań LINQ (technologia umożliwia zadawanie pytań na obiektach). Preferuję te drugie podejście (kod pisze się szybciej i łatwiej go przetestować) i takiego też będę używał w poniższych przykładach.
Kod podzielony jest na dwie główne metody. Pierwsza część odpowiedzialna jest za pobieranie wszystkich linków do wpisów blogowych. Druga metoda pobiera stronę z edycją każdego wpisu i uszykuje szczegółowe dane.
Pobieranie listy wpisów
public async Task<List<Post>> GetBlogMainStatistics(int pageNo, List<Post> postLink, HttpClient httpClient)
{
var request = new HttpRequestMessage(HttpMethod.Get, new Uri(Const.BlogPrefix + pageNo + ".html"));
var response = await httpClient.SendRequestAsync(request);
HtmlDocument doc = new HtmlDocument();
doc.LoadHtml(await response.Content.ReadAsStringAsync());
var divWithLinks = doc.DocumentNode.Descendants("div")
.Where(d => d.Attributes.Contains("class") &&
d.Attributes["class"].Value.Contains("contentText"))
.FirstOrDefault();
if (divWithLinks != null)
{
int lastOrderId = postLink.Select(x => x.OrderId).LastOrDefault();
divWithLinks.Descendants("tr").ToList().ForEach(x =>
{
var elemA = x.Descendants("a").FirstOrDefault();
var elemSpan = x.Descendants("span").FirstOrDefault();
if (elemA != null && elemSpan != null)
{
var newPost = new Post()
{
Title = elemA.InnerText,
Url = elemA.Attributes["href"].Value,
IsPublished = elemSpan.InnerText == Const.PostStatusPublished,
IsHomePage = elemSpan.Attributes.Contains("class") &&
elemSpan.Attributes["class"].Value.Contains(Const.PostHomePage),
OrderId = ++lastOrderId
};
newPost.Id = newPost.Url
.Split(new string[] { ",", ".html" }, StringSplitOptions.RemoveEmptyEntries)
.Reverse().First();
postLink.Add(newPost);
}
});
}
var nextLink = doc.DocumentNode.Descendants("div")
.Where(d => d.Attributes.Contains("class") &&
d.Attributes["class"].Value.Contains("controls"))
.FirstOrDefault();
var nextUrl = (Const.BlogPrefix + (pageNo + 1) + ".html");
if (nextLink != null && nextLink.Descendants("a").Where(a =>
a.Attributes.Contains("href") &&
a.Attributes["href"].Value == nextUrl).Count() > 0)
{
await GetBlogMainStatistics((pageNo + 1), postLink, httpClient);
}
return postLink;
}
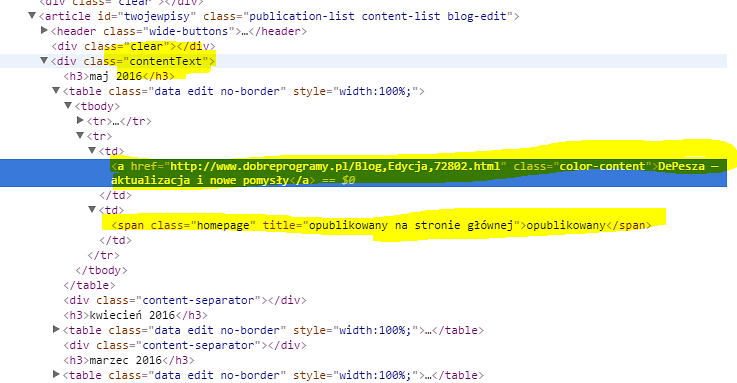
Omówmy teraz funkcję GetBlogMainStatistics . Na początku pobieramy poprzez HttpClient jedną stronę ze statystykami ( pageNo jest aktualną stroną), gdzie strona pojedyncza ma adres:
"http://www.dobreprogramy.pl/MojBlog," + pageNo + ".html"
Ładowanie danych do parsowania przez HTML Agility Pack jest proste, wystarczy podać string z czystym Htmlem (tutaj jest to pobrany dokument z odpowiedzi z serwera):
HtmlDocument doc = new HtmlDocument();
doc.LoadHtml(await response.Content.ReadAsStringAsync());
W kolejnym kroku tworzymy zapytanie LINQ, które pobierze główny element ( div z klasą css: contentText ) zawierający tablicę z poszczególnymi linkami do wpisów:
var divWithLinks = doc.DocumentNode.Descendants("div")
.Where(d => d.Attributes.Contains("class") &&
d.Attributes["class"].Value.Contains("contentText"))
.FirstOrDefault();
Zapytanie w LINQ wygląda znacznie przyjemniej niż gdybyśmy używali XPatha. Korzeniem jest DocumentNode, z którego pobieramy wszystkich potomków, którzy są elementami div . Szukamy elementów div , które posiadają atrybut classs , a w nim wartość contentText . Na tym schemacie opiera się całość działań na danym dokumencie HTML.
Teraz będąc w głównym elemencie div pobieramy wszystkie wpisy na stronie:
int lastOrderId = postLink.Select(x => x.OrderId).LastOrDefault();
divWithLinks.Descendants("tr").ToList().ForEach(x =>
{
var elemA = x.Descendants("a").FirstOrDefault();
var elemSpan = x.Descendants("span").FirstOrDefault();
if (elemA != null && elemSpan != null)
{
var newPost = new Post()
{
Title = elemA.InnerText,
Url = elemA.Attributes["href"].Value,
IsPublished = elemSpan.InnerText == Const.PostStatusPublished,
IsHomePage = elemSpan.Attributes.Contains("class") &&
elemSpan.Attributes["class"].Value.Contains(Const.PostHomePage),
OrderId = ++lastOrderId
};
newPost.Id = newPost.Url
.Split(new string[] { ",", ".html" }, StringSplitOptions.RemoveEmptyEntries)
.Reverse().First();
postLink.Add(newPost);
}
});
Z każdego elementu tr uzyskujemy nazwę wpisu, adres, a także status wpisu. Z adresu url można także wydobyć Id wpisu. Link jest ustandaryzowany i wygląda tak:
"http://www.dobreprogramy.pl/Blog,Edycja,"+ID_WPISU"+.html"
Funkcja GetBlogMainStatistics jest rekurencyjna i warunek stopu jest sprawdzeniem czy w pasku nawigacyjnym (na dole strony) jest adres z kolejną stroną z listą blogów:
var nextLink = doc.DocumentNode.Descendants("div")
.Where(d => d.Attributes.Contains("class") &&
d.Attributes["class"].Value.Contains("controls"))
.FirstOrDefault();
var nextUrl = (Const.BlogPrefix + (pageNo + 1) + ".html");
if (nextLink != null && nextLink.Descendants("a").Where(a =>
a.Attributes.Contains("href") &&
a.Attributes["href"].Value == nextUrl).Count() > 0)
{
await GetBlogMainStatistics((pageNo + 1), postLink, httpClient);
}
W ten sposób uzyskamy listę z blogami. Kolejnym etapem jest przejrzenie jej i pobranie każdej strony z edycją wpisu, aby uzyskać dane odnośnie liczby wyświetleń i komentarzy.
Pobieranie wyświetleń i komentarzy na blogu
Cała funkcja jest znacznie prostsza niż poprzednia:
public async Task<List<Post>> GetBlogCounters(List<Post> postLink, HttpClient httpClient)
{
HtmlDocument doc = new HtmlDocument();
foreach (var post in postLink)
{
var request = new HttpRequestMessage(HttpMethod.Get, new Uri(post.Url));
var response = await httpClient.SendRequestAsync(request);
doc.LoadHtml(await response.Content.ReadAsStringAsync());
var details = doc.DocumentNode.Descendants("section")
.Where(d => d.Attributes.Contains("class") &&
d.Attributes["class"].Value.Contains("user-info")).LastOrDefault();
if (details != null)
{
var divs = details.Descendants("div").ToList();
if (divs.Count >= 12)
{
post.VisitorsCounter = int.Parse(divs[9].InnerText);
post.CommentsCounter = int.Parse(divs[12].InnerText);
post.DateLastModification = DateTime.ParseExact(divs[5].InnerText,
"dd.MM.yyyy HH:mm", CultureInfo.InvariantCulture);
}
}
}
return postLink;
}
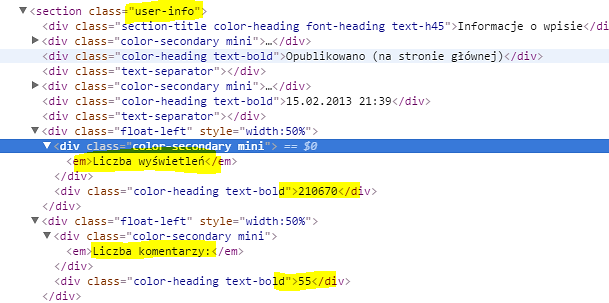
W pętli pobieramy stronę HTML z edycją każdego wpisu i dobieramy się do tabelki ze statystykami (posiada ona klasę css user-info ). Tutaj już parsujemy ilość wpisów i wyświetlenia na typ int, a także uzyskuję datę ostatniej edycji.
Na koniec uzyskamy szczegółowe dane odnośnie każdego wpisu. Tak przygotowane statystyki będą wędrować do użytkownika.
DePesza - kolejna wersja
Jak już wspomniałem niedługo wrzucę do marketu nową wersję DePeszy. Prócz szczegółowych statystyk z bloga, nowa wersja będzie posiadać dużo poprawek, ulepszeń i kilka ciekawych odświeżonych elementów. Na pewno się nie zawiedziecie. Mam nadzieję, że zmiany przypadną wszystkimi do gustu.
DePesza dostępna jest w markecie Windows 10 (desktop i mobile). Bezpośredni link: DePesza.
Aktualne źródła można znaleźć na GitHub pod adresem: https://github.com/djfoxer/dp.notification

Komentarze
Prześlij komentarz